Thanks a lot for the recommendation, i'll check it out. The problem is that i look for something generic, so it would not really help to send some sample clip because it should do a good job on any kind of input (movies, shows, even music clips etc..)
Anyway, i dont want to capture your thread so back to the topic.
Of course you can come up with ffmpeg commands to mix in the voice clips after X seconds or such but in my head, the easiest solution is to work like this:

- openbumpout.png (36.27 KiB) Viewed 9899 times
Each section separated by black line represents one prepared audio file, so you got ready to use, static wav files for:
*) opener
*) music bed 1
*) bumper
*) music bed 2
*) outro
This way, you only need to collect talk1 and 2 from userinput/watchfolder and you have a very easy time to mix talk1+musicbed1 and talk2+musicbed2 in 2 individual simple ffmpeg commands.
Code: Select all
ffmpeg -i \\server\share\static_audios\musicbed1.wav -i \\server\some\folder\talk1.wav -filter_complex amix=inputs=2 -shortest "%s_job_work%\mix1.wav"
Same for musicbed2+talk2.
After that, you just need to stitch opener, mix1, bumper, mix2 and outro into a single file.
This keeps everything very simple to set up and to debug. E.g. you don't need to specify any duration or other variables if you just make sure that the static files music bed1 and 2 are much longer than the actual voiceover can possibly be. The -shortest option would just hard-cut music1 at the end of voiceover.
Regarding webinterface submission, i fear you will need to spend a little time to get into it but in my head, from a user perspective the interface could look like this. The user has to browse for files on the left side and select exactly 2 files for the right side. The workflow can optionally present some options to the user (in my example, i present 3 dropdowns that would link to static wav files on the NAS).
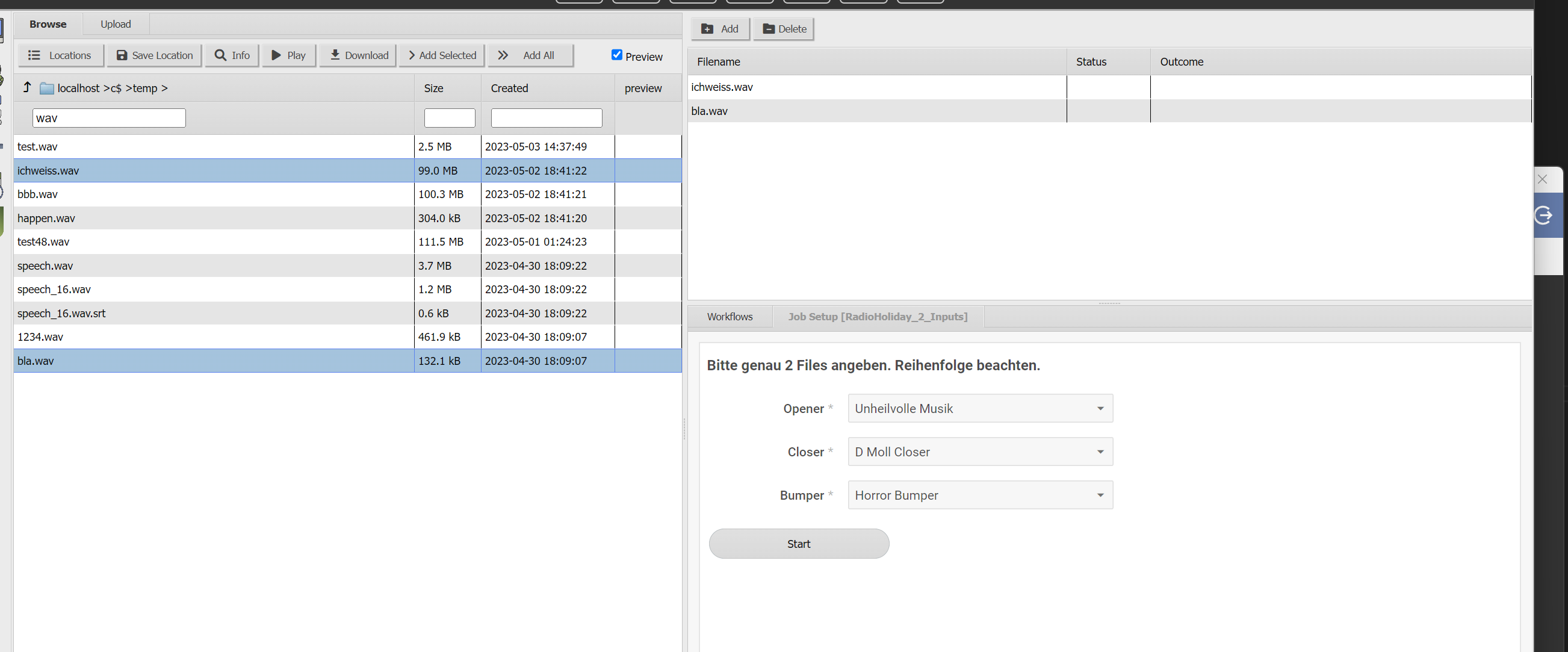
- webint123.png (113.6 KiB) Viewed 9899 times
This way you can provide some helping text to the user, explaining what he has got to do and in your workflow you would not need to check and search for any files, you would just work with the 2 files the user provided.
